技术支持
如有技术问题,请看这里
FAQ
1. 分词时候需要进行扩展字典,自定义字典的格式是怎样的,如何把自定义的字典加载进去?
需要在本地编译ltp(推荐使用linux),编译后调用静态链接库,具体方法见这里:从源代码编译安装LTP 关于词典格式,词的分割用空格。例如:
我 是 中国 人 。 疯狂 的 兔子2. 采用句法分析时候,是不是要先分好词,然后将分词结果输入到句法分析接口中才能找出句子的依存关系?但我看到bin下面的ltp_test是直接给定待分析文本的路径就可以直接给出句子的依存关系(其中包括分词,词性都分好了),那我可不可以直接给定自定义的分词字典?
如果您需要使用外部字典做分词,又想使用依存句法分析,推荐您使用lib来调用ltp,具体可以参考http://t.cn/zRcKbd4目录下的样例文件。
3.如何指定自己自定义字典中词的词性呢?我发现根据自己定义的字典,有些词性分的有问题。
现在只有分词模块支持词典,词性标注还没加入词典支持,后续版本会考虑引入词典机制。
4. 我在本地使用ltp的时候出现 [ERROR] … in LTP::wordseg, failed to load segmentor resource 是怎么回事儿?
出现这个情况,是因为模型文件不存在或路径与配置文件不相符。在ltp运行时,首先需要知道配置文件,这是在调用程序是指定。配置文件中指定了模型的路径,如下所示:
segmentor-model = ltp_data/cws.model postagger-model = ltp_data/pos.model parser-model = ltp_data/parser.model ner-model = ltp_data/ner.model srl-data = ltp_data/srl5. 我在用C# SDK的时候显示出现了乱码,如何解决?
目前ltp sdk只支持utf-8编码。在Windows下开发,如VS2008,默认用gbk读取文件。而有时我们的文件时其他编码,如“utf-8”,在读取文件的时候,需要设置读取文件的编码,以C#SDK为例做如下修改:ReadAllLines(strSentFile,Encoding.UTF8)。再如用Eclipse下的Java sdk,我们可以先右键工程Properties->Resource->Text file encoding,选择Other并设置为utf-8。之后子根据文件自身的编码读取就可以了。还有,不建议复制粘贴代码,这样很容易一些默认编码的原因造成程序乱码。
6. Github上关于在windows下使用LTP的文档还是不太详细,能否详细受一下流程?
用Cmake编译LTP源代码。Cmake是编译LTP的辅助工具,需要用户下载windows版本的Cmake。
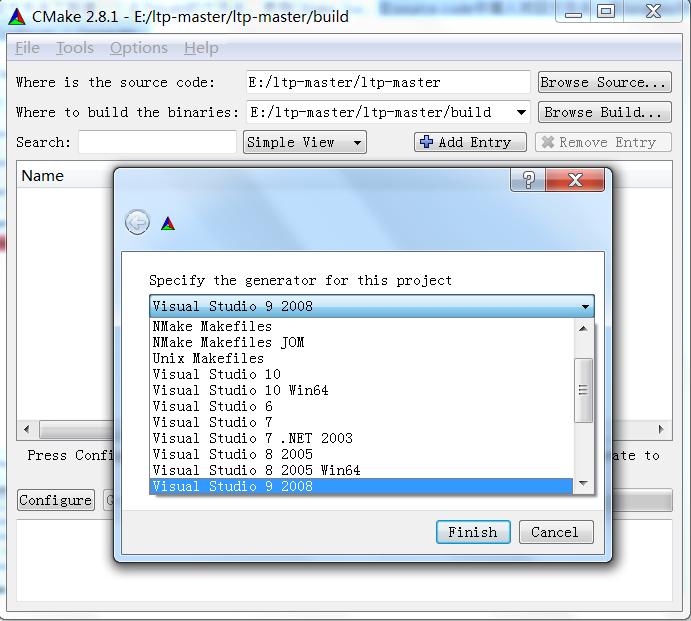
图1 cmake示例
在项目文件夹下创建build文件夹,打开Cmake gui,在source code中填入项目文件夹,在binaries中填入build文件夹,然后Configure,选择VS 2008作为编译器之后再Generate,如图1所示。之后在build文件夹下得到ALL_BUILD、RUN_TESTS、ZERO_CHECK三个VC Project。使用VS打开ALL_BUILD项目,BUILD->Configuration Manager->Activesolution_configuration:Release,即选择Relaese方式构建项目,然后Build项目。这样在bin文件夹下生成了ltp_test.ext,在lib文件夹下生成了.lib、.dll文件。这样LTP就编译完成了。
联系我们
技术支持
与语言技术平台以及语言云相关的技术问题,您可以从邮件列表中找到答案,或者发邮件联系作者。
商业协议购买
语言技术平台(LTP)及语言云面向非盈利组织(如大学、科研院所等)以及个人研究者的非盈利项目开放源代码;对于上述组织或个人将该平台用于盈利目的的或任何盈利组织,若要使用相关的技术和服务,则需要购买商业版授权。与开源版本相比,商业版精度更高、速度更快、功能更丰富,并提供相应的售后服务。凡涉及商业版授权问题,请发邮件到car@ir.hit.edu.cn洽商。